上图为某公司近半年的留存率变化情况(数据为举例),通过图中我们发现留存率随着时间逐渐减少,这是一个总体结果的呈现,而当我们想要了解更细节的信息,比如说:
有什么办法能让我们深挖数据呢?同期组群分析可以解决。 二、使用Cohort Analysis组群分析剖析数据Cohort Analysis同期组群分析,即针对不同分组的用户在相同的时段内的分析方法。通过以下步骤我们来看看如何运用组群分析剖析留存分析的问题。 1. 建立分析框架:分组+时间
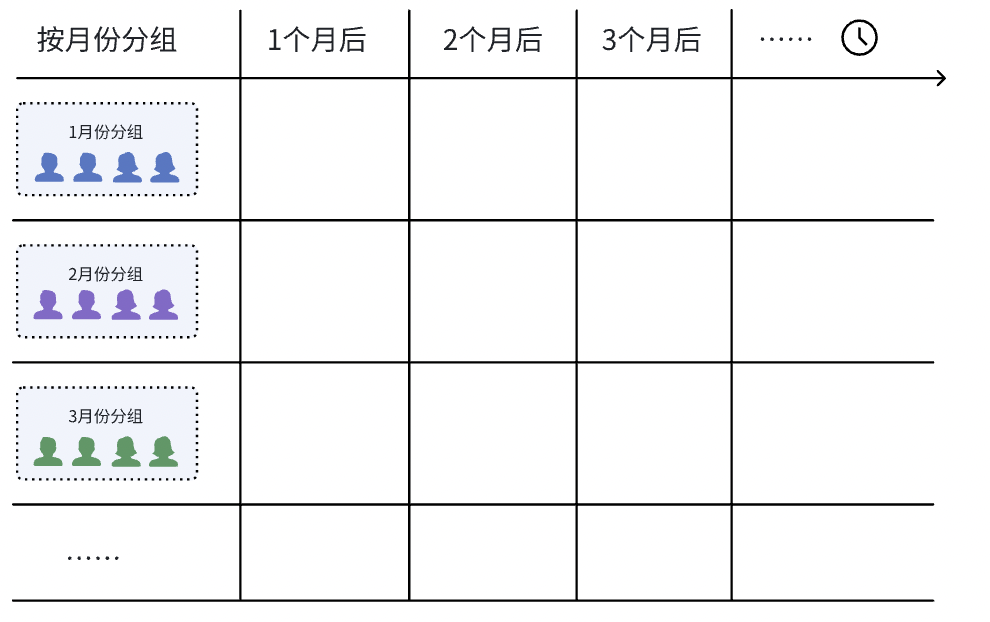 2. 定义研究的主体变量,采集数据填充在通过坐标轴建立好分组标准和时间周期粒度后,我们需要确定研究的主体变量。在例子留存率分析中的主体研究对象是“每月下的新增用户”,我们把它放在对应分组的旁边,代表的是当前月份分组下对应的“新增用户”数值。  当用户群、时间、研究主体都确定后,我们可以进行数据的采集及填充。随着时间的推移,年初至7月份的数据: 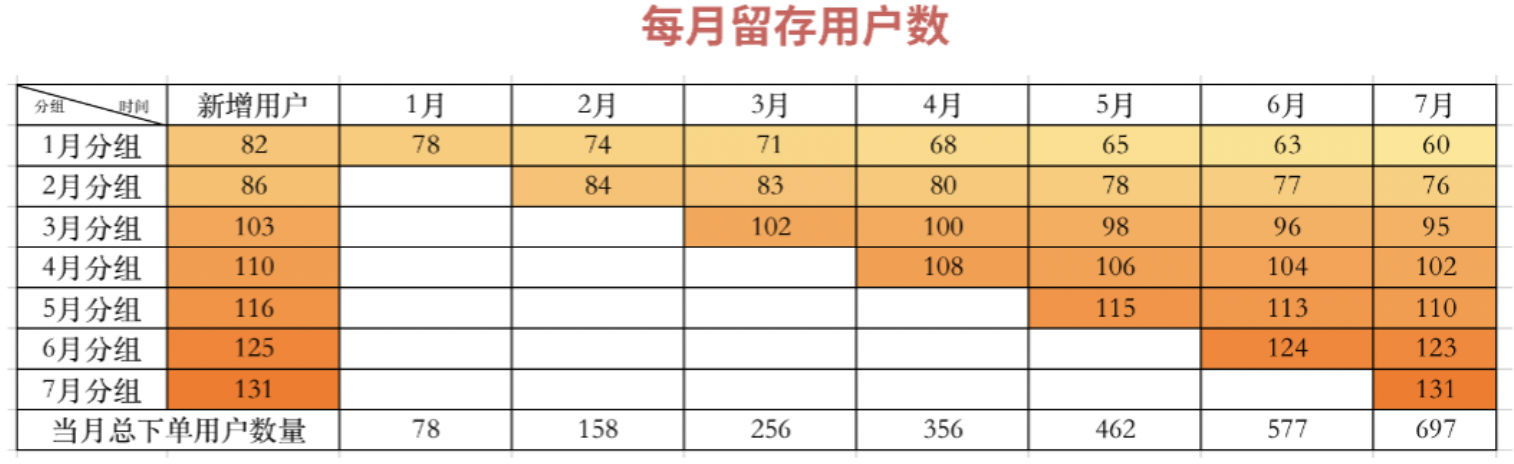 分别从横轴及纵轴这二维的角度来展开剖析数据: 1)横向比较:时间的延展性 横轴的视角是具体分组下随着时间变化的情况,分组间体现了时间的延展性,你可以看到每个月新增的用户留存随着时间的推移的数量变化情况。观察图表我们可以发现的问题是:
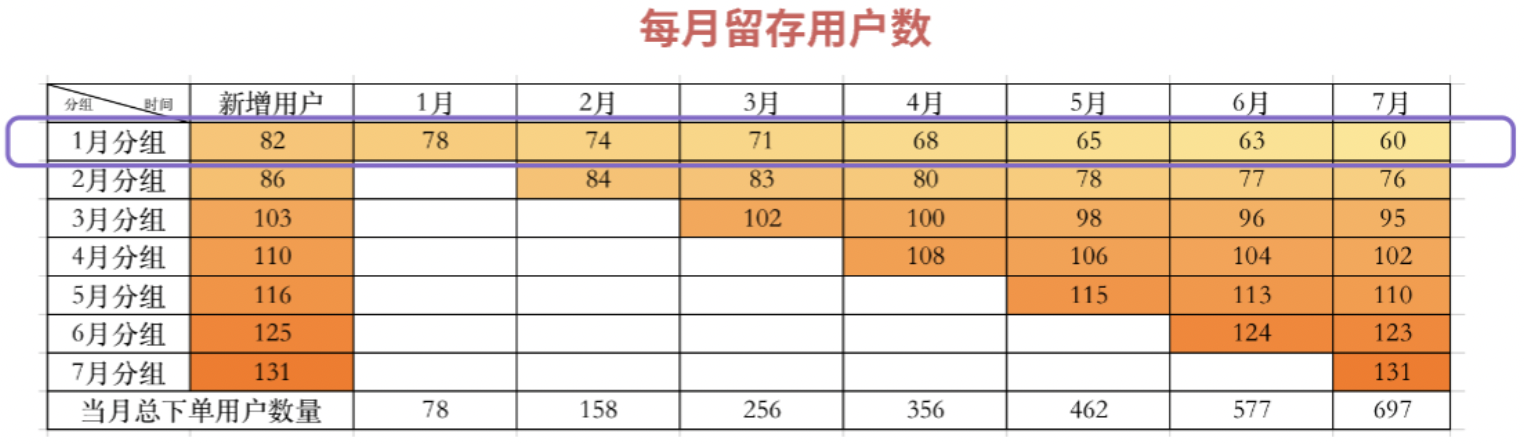 2)纵向比较:聚焦时间段下的细分结构 纵向的数据,即具体月份下的数据是对每期分组的新增用户进行累加,各分群组成结构清晰可见。  针对留存的分析,转化成留存率的视角,观察每月新增用户、每月下各期组成分群的留存率变化趋势,理想态是要提升的,说明数据的留存比之前更好,体现出公司不断在产品功能上进行优化,使得留存率提升。如果发现背离理想态的状况,再聚焦异常的节点进行分析。 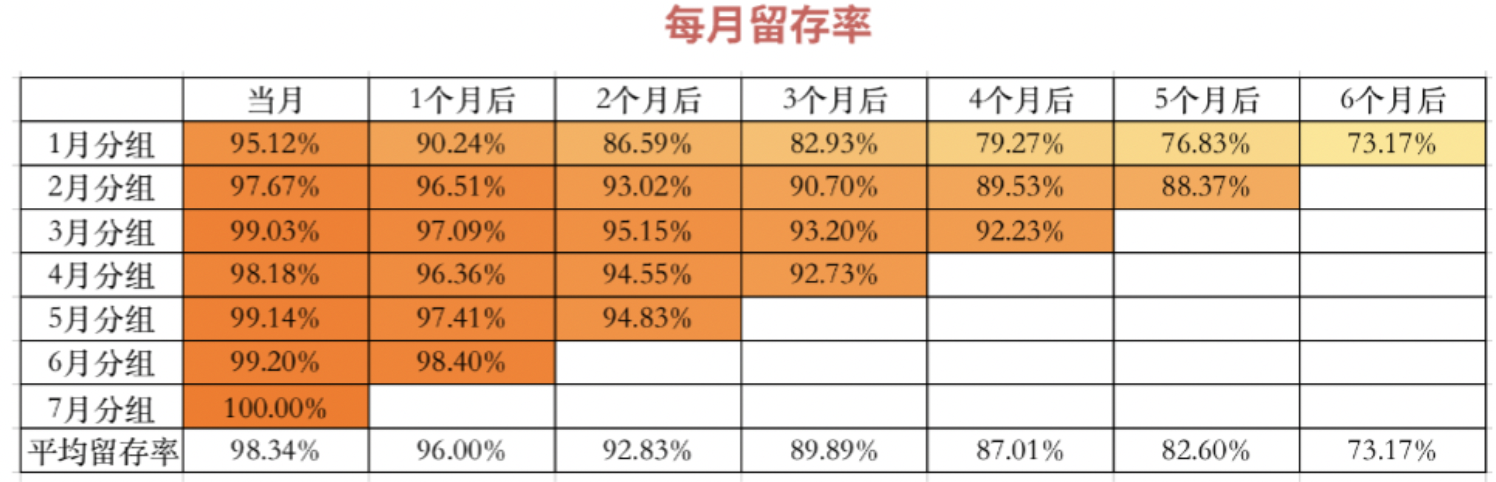 另外谈一下增强数据的可读性,可以通过对数值区间进行颜色深浅的设置,或者将横纵轴分别转化成折线图,使得对于数据的波动幅度得到更直观的呈现。 三、灵活运用分组分析上例留存率问题已经简要说明了组群分析的基本使用步骤,它达成了把问题拆解到时间维度呈现变化趋势及组成结构。那么Cohort Analysis组群分还能怎么灵活运用?它有没有局限性呢?我们尝试着抽象出它的几类运用模式。首先,看下它的基础框架是这样: 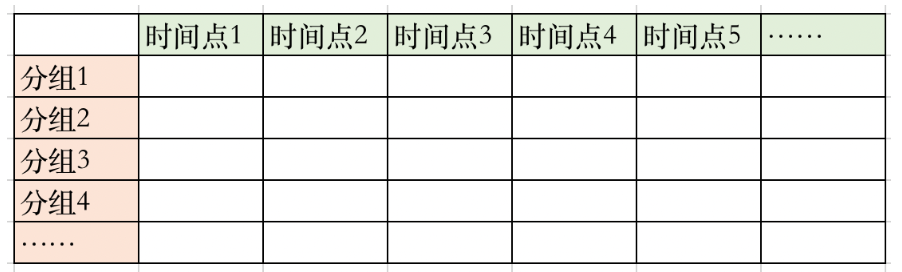 1. 研究纵轴的分组对象:可以是时间、人、事/物1)“时间”为纵轴的分组 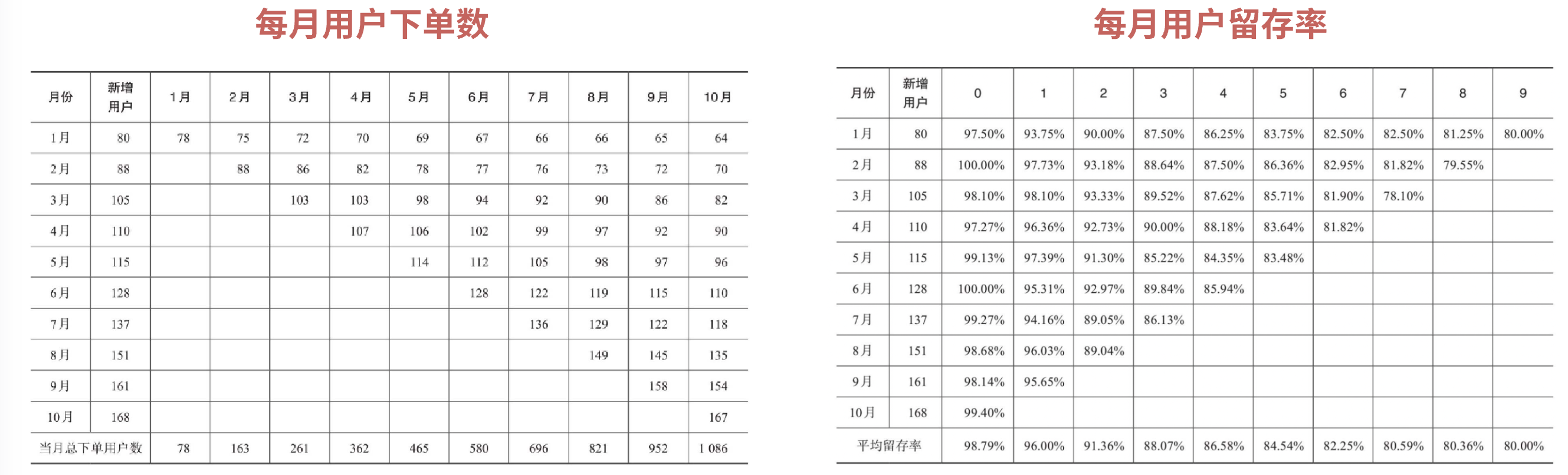 它的特点为分组是对不同时期进入的用户,分别考察其后续行为的变化情况,这个特性决定了每期分组下存在持续新增用户,此时的分析才有意义。 由于C端类产品用户是独立的个体,单独使用,满足这种情况;而B端类产品就不适用了,B端类产品的用户往往是在系统上线时,大批量应公司要求开始使用,后续零星的新员工继续加入使用,在每期分组下不满足有持续新增用户。 再说说此类表格数据的呈现形式,由于是对不同时间批次的数据进行收集,在表格数据呈现形式上是三角形。 2)“人(用户群)”、“事/物”为纵轴的分组
它们在表格数据呈现形式上是整齐划一,也是我们最常见的柱状图/曲线图表格化的呈现。 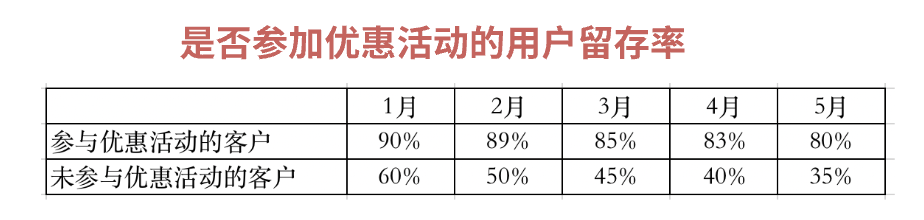 2. 研究横向时间轴的划分方式1)如何设定观察时间的起点 a.留出对比时间段:若要突出某项功能上线前后对产品的影响和贡献,需要将观察时间的起点提前设定,留出一定的时间好对比功能前后的变化。 b.结合用户使用频次特点:这里要说说C端和B端用户的差异。C端产品服务于用户个人,特点是主要用户群体对于核心功能高频的使用。B端用户是企业内部的用户群,他们使用各自职能下需要的系统功能,并且个别使用还呈现出周期性的特点,比如:月度的工资计算、季度的物料盘点、周期性的物品采购等等。因此,在对于B端产品的观察时,需要针对到具体角色使用的时段下研究才有意义。 2)设置时间间隔的考量 时间间隔的大小代表了多久分析一次,设置合理的时间间隔的大小,有助于降低时间中的噪音。 当研究更聚焦宏观周期时,时间段的间隔倾向设置得较大,比如按月或按年进行分割;当聚焦细节变化时,时间段的设计的间隔设置得相对较小,比如:按周、按天、按小时段等等。 3)事件记录 记录研究全时段内的发生事件,便于在对时间节点进行分析时有落脚点,成为相关性分析中的研究事件。 以上是搭建组群分析框架的思路,在组群分析方法搭建好之后,是对于数据的收集、观察、异常问题的定位,枚举可能性的原因,通过相关性分析聚焦具体的原因。 本文由@tomato 原创发布于人人都是产品经理,未经许可,禁止转载。 题图来自 Unsplash,基于 CC0 协议。 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。 |