
|
当你面对“原子指标需要支持开窗函数吗”这个问题时,你会如何回答?这篇文章里,作者结合案例和过往经验,对开窗、指标管理、原子指标等概念及相关问题做了解读,不妨来看一下。  数仓开发同事看了这个原子指标管理的界面,然后问了上文提到的问题:原子指标能不能支持开窗函数。我反问了下,为啥要支持开窗?同事当时说的原话我不太记得了,大概说的是:某些指标是要开窗统计排名。比如(假设),教育场景里,某个报表里有这两个指标。  销售金额TOP1课程,很像是用来修饰指标的前缀(修饰词),但又是基于对指标的排序而来的。 已知,原子指标要定义指标取数的逻辑,开窗函数是一种计算方式,那么,原子指标的定义里面,是否要囊括对开窗函数的定义呢?我转身看竞品(DataArts Studio_新建原子指标)找答案,但是竞品没支持。  不仅仅华为不支持,其他好几个大厂竞品都没涉及到这点。完蛋,我好像进入一个没人涉足的无人区了,咋搞?当然,我可以很简单做个决策:相信大厂,照抄。并且以此说服同事,我可以说,大厂的好多的竞品没做,肯定是有道理。但是到底为什么竞品不支持开窗呢?我始终不明白。 我了解了实际情况,管理、推荐的场景里,确实有些指标是排名性质的,看似这个诉求也合理。而且,排名方面,还可以继续演化,以直播场景为例。比如按照多个指标排名后,最终分出来主播的级别,然后日常要看S、A、B级主播带货金额占总体GMV的比例。 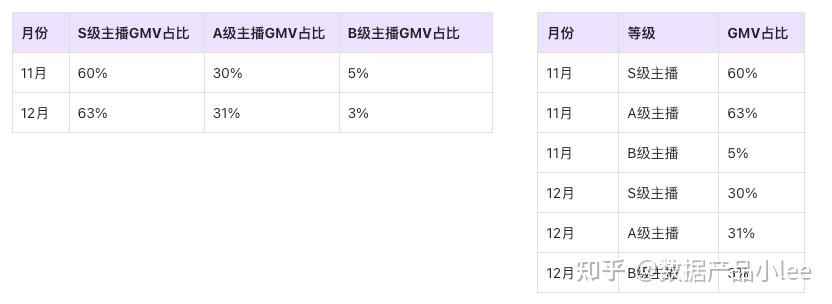 在企业里,你可能会看到两种状态的表格,描述的业务结果是一样的,但是表头、行数、列数有一些差异(差异就在于,修饰词是否单独列出来作为维度,以后有机会再讲)到底要不要支持呢?要不要探究下呢?理解开窗,才能知道到底要不要。 二、什么是开窗,为什么要开窗?我们人眼所看到的内容,都是光照到物体上的反射,打开窗户,外面的光才能照进来。 开窗的大小,决定了进入到窗内的光的多少,也影响了窗内人获取信息的量。  人所看到的内容,取决于看的视角,从不同的角度看,信息也不同。 还记得小学课文里的杨桃吗?有的角度看杨桃,像个五角星。再比如,苏轼在《题西林壁》中写道:横看成岭侧成峰,远近高低各不同。不识庐山真面目,只缘身在此山中”。 假如,我们待在一个房间内,我们认为窗是相对静止的。调整我们的视角,能看到不同的内容,可以理解为从不同的角度(维度)去分析事物。除此以外,也有移动的窗。 就如图片所示,当我们坐在火车上,视角固定,窗户常开,虽然你人不动,但是你会看到不断变化的内容,不同物体的光会透过窗户(信息)不断映入你的眼睛。有了这个基础,我们再去理解数据世界的开窗函数。 开窗函数是一种在数据库查询中使用的强大工具,它能够在一个数据集上进行复杂的序列比较和计算。 在SQL中,开窗函数可以用于各种计算,包括聚合运算、排名、移动平均等,而不改变返回行的数量。以下是一个简单的例子:假设我们有一张名为sales的表格,其中包含了每天的销售数据,该表具有以下结构:
如果我们想计算过去7天的滚动平均销售额,则可以用如下SQL查询: SELECT sale_date, amount, AVG(amount) OVER (ORDER BY sale_date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) AS rolling_avg_sales FROM sales; 这个查询中的关键部分是开窗函数AVG(amount) OVER (…):
执行这个查询后,每一行都会新增一个rolling_avg_sales字段,表示从当前行开始往前数7天内(包括当前行)的平均销售额。备注: 不同的SQL数据库管理系统在处理边界情况(例如,当没有足够的数据计算七天平均时)的默认行为可能略有不同。 然后,我们结合案例来看看开窗函数定义的指标。 假如,我们是一家网店的店主,本月新上了一个品类,然后系统记录了该品类1-20号的当天销售金额,也统计了环比昨天的指标。如下左边。我们也基于这两个指标制作对应的业绩变化图。 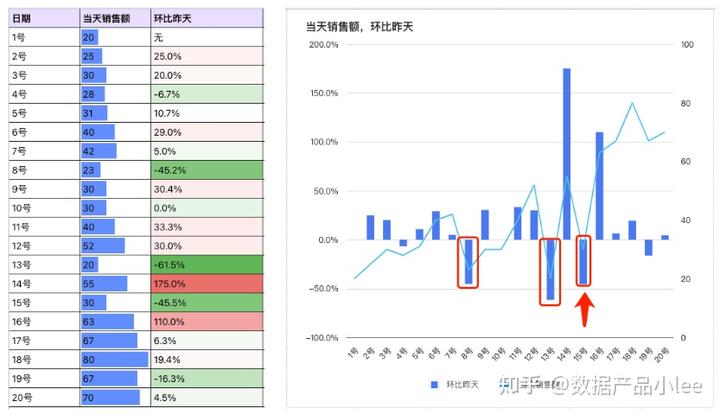 而当我们感受到2次比较大的业绩下滑,在第3次业绩下滑的时候,要不要进行调整销售策略呢?调整的依据是什么呢?尤其14号的业绩刚刚有突破,而15号又猛烈下滑。 这个时候,我们就可以用开窗函数来看平均的销售情况,而不是被某一天或两天的异常高低销售额所影响,我们可以使用7天滚动平均销售金额这个指标(如下图)  结合7天滚动平均销售金额来看,虽然业绩有起伏波动,尤其是红色框中的部分,滚动平均销售金额的波动并没有那么大,且在小幅下降后便逐步上升如果在原子指标定义中需要考虑时间序列分析、累积计算或者比较不同时期的数据,那么开窗函数就非常有必要。 当然,在真实的应用场景中,我们还需要考虑到特殊情况,比如业务调整、节假日或者其他非营业日没有销售数据的情况。 三、回看,到底要不要支持开窗?开窗有意义吗?有。那系统层面能支持开窗吗?能。要支持开窗吗?等等,再想想,其实还有一个问题。 为什么看到很多竞品系统,在定义原子指标计算逻辑时,都要求先指定对应的来源表呢?而且一般都是事实表,这当中有什么关系吗? 正好,在上篇文章里讲到过这个问题:数仓分层后,原子指标如何指定来源事实表。 当中说道:我们的目标重点是保持清晰的指标定义和一致的取数口径,即使在不同的聚合层级之间,销售金额指标的计算规则也应该是一致的。 等等,如果有两个表,一个原始表,一个开窗的结果表,那是不是可以基于开窗处理后的结果表来定义指标呢?嗯,把这种开窗的计算逻辑前置到表的ETL脚本里去,原子指标这层,屏蔽掉这个逻辑。 我们再看看开窗函数,到底是在做什么操作? 在上面的案例里,你也看到了,在某些日期内做开窗计算,是没有结果的。 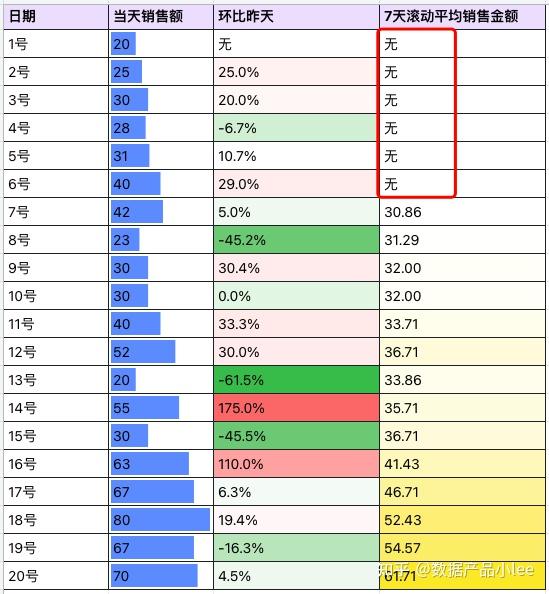 当数据缺漏时,就像开的窗户对着一块黑洞。 因为窗户设定的范围很大,但是数据的范围没那么大(就好像,开的窗户里有一部分对着黑洞,光压根从黑洞里跑不出来,那肯定看不到。 而且,案例中开窗是要按照设定的窗口范围取一些历史数据计算的,无意间就利用时间修饰了指标。时间是什么?可以理解是维度,比如日期,也可以理解是时间周期,近1天、近7天。 其实环比昨日也涉及到了时间周期。还记得之前文章指标管理必知的真相:订单事实表里没有原子指标引用的公式吗?派生指标 = 原子指标 + 时间周期 + 修饰词  再问问自己:开窗函数定义的指标是原子指标吗?诶,好像不是。 这时候,我们再回看定义,在指标管理中,原子指标通常指的是最基本、不可再分的数据点,这些数据点用来构建更复杂的计算指标或衍生指标。 例如,日销售额、用户访问量等都可以被看作是原子指标。开窗的指标,相当于是借用有时间含义的指标进行了口径定义,且只能是在时间往前推移的情况下(也就是有了时间周期的情况下),才能有正确的计算结果。 故而,开窗函数修饰的指标,不是原子指标。原子指标,不应该支持开窗函数。 四、问题的本质:理解指标、表、以及指标和表的关系1)深入理解不可再分 “不可再分”的原子指标,指的是在特定的业务情境下,该指标已经是最简单、最基础的数据度量,无法被进一步分解为更小的单位或子指标。窗口这个词,其实不能完全表达含义,时间列车在滚滚向前,我们哪怕只从固定的视角看数据,但是这个数据也一直在变化。 例如,在销售分析中,“日销售金额”可以看作是一个原子指标。它由当天所有销售交易的金额总和组成,自身并不会进一步分解为更细的指标。当然,“日销售金额”可能来源于多个“单笔交易金额”,但在日销售额这个层面上,我们通常把它视为一个整体,作为分析的基点。 2)深入理解粒度 分析的基点,这就是为什么数据仓库在选定业务过程后,接下来就是声明粒度的原因。可以回看这篇文章:数仓避坑-整明白懂粒度如果一个公司想要分析产品销售数据,那么“单个产品的销售数量”也可以被认为是一个原子指标,因为它代表了最基本的销售单位计数,不涉及到更深层次的拆分。 这样的原子指标有助于建立一个清晰、简洁的数据体系,它们是构建复杂报告、仪表板和高级分析(如预测模型)所依赖的基石。通过对多个原子指标进行组合和运算,可以创建复杂的衍生指标,如销售增长率、用户留存率等。 3)脱离具体的表谈论指标,是没有意义的 指标是为了衡量、跟踪或比较特定现象或结果而设定的具体数值或标准。离开具体的表定义指标和取数口径,一个指标可能就会失去其原有的明确含义和测量价值。 如果没有了明确的定义和取数口径,就很难保证数据的一致性和准确性,进而影响数据分析和决策的有效性。 4)指标定义的问题,可以通过增加分层表来解决 当我们要依赖其他指标进行计算,我们可以先定义好事实表,加工好对应的指标,然后从定义好的事实表里面取值。 这样也有个好处:利用表对指标的依赖逻辑进行一个解耦。不至于让指标的计算口径定义太过于复杂,比如,我们看某个指标,能知道这个指标是从某个表的某个字段基于什么方式进行计算,就可以了。至于说,依赖的表是怎么加工出来,数据是否准确,那是上一层定义的事情了。 5)表分层之后数据的一致性问题,需要质量监测来解决 紧接问题4,开窗是要开的,我们在指标所依赖的表的ETL里定义好,算好即可。如果粒度有很多,最粗粒度的指标肯定是有多种方式来汇聚出来的。比如,年度收入,可以从小时收入、天收入、周收入、月收入汇总出来。 以终为始来看,咱也不管是咋汇聚的了,咱就只要求:最终出来的结果是对的,多种方式产出的结果是一致的(都对!)。这,就是数据质量里的准确性、一致性。 以上,感谢阅读~ 专栏作家 Lee,公众号:数据产品小lee,人人都是产品经理专栏作家。关注直播、短视频和文娱领域、擅长数据架构、CDP及数据治理相关工作。 本文原创发布于人人都是产品经理,未经许可,禁止转载 题图来自 Unsplash,基于 CC0 协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。 |

















